Du leste kanskje om RAG i Torstein sin bloggpost? For å få til dette trenger du å kunne søke semantisk i dine egne data.
Jeg tenker å vise litt mer om hvordan vi kan bruke vektor-representasjoner av tekst, såkalte text-embeddings til å gjøre semantiske søk, og vil også implementere dette i typescript med nodejs, PostgreSQL sin vektordatabase (pgvector) og Ollama.
¶Semantisk søk
Med semantisk søk mener vi et søk der man prøver å forstå meningen bak en forespørsel i stedet for bare å matche eksakte nøkkelord. Eks. om vi søker etter «rimelig, slitesterk ryggsekk for turgåing», kan et semantisk søk forstå at «rimelig» refererer til pris, «slitesterk» til materialkvalitet og «ryggsekk for turgåing» til spesifikke bruksområder. Resultatene blir dermed tilpasset basert på attributter og intensjoner, ikke bare nøkkelord.
Vi er jo blitt vant med å bruke semantiske søk overalt på nettet, men hva om vi vil tilby søk på data som ikke er tilgjengelig på internett? Eller hva om vi vil spørre en språkmodell om våre interne data, altså en RAG (Retrieval Augmented Generator)? Da trenger vi en måte å søke frem aktuelle data basert på semantisk innhold.
Velkommen til en kort introduksjon til bruk av tekstvektorer, eller vektor-representasjoner av tekst (på engelsk: text embeddings, eller bare embeddings). Vi skal først ta et kort dykk i hva dette egentlig er, og etterpå vise hvordan du enkelt kan implementere semantisk søk på egne data ved hjelp av PostgreSQL pgvector og Ollama nomic-embed-text.
¶Representasjon av tekst som vektorer
Dette er noe som moderne maskinlæring har gjort mulig. Det er modeller som er trent opp på store mengder tekst, og som tar tekst inn og returnerer en vektor, altså en liste med tall, typisk i 512, 768, 1024, 1536 eller 2048 dimensjoner. Og – selve poenget – denne vektoren har den helt spesielle egenskapen at:
Dette er forskjellig fra språkmodeller, som er trent opp til å forutsi neste ord i en tekst, men teknologiene har mange fellestrekk likevel. De bruker f.eks. transformer arkitekturen, som er en type nevrale nettverk som er spesielt egnet til å forstå sammenhenger i tekst.
Litt historikk
For den historisk interesserte er det verdt å nevne at moderne tekst-vektoriseringsalgoritmer bygger videre på ideen som ble popularisert av Google i 2013, kalt word2vec. Den lagde vektorer av enkeltord, og hadde den fantastiske egenskapen at man kunne gjøre vektor-operasjoner på ord: F.eks. at er Dronning ≈ Konge – Mann + Kvinne
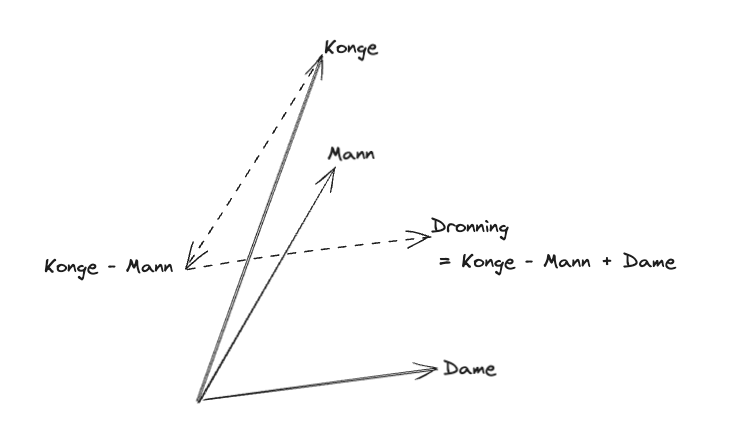
Denne algoritmen var et gjennombrudd når den kom, mye fordi den ble levert med åpen kildekode. Selv om den bare opererer på enkeltord, viser den prinsippet i moderne tekst-vektoriserings-algoritmer, nemlig at det er semantikken i teksten som bestemmer vektoren.
Avstand mellom vektorer
Bare kort om hvordan man måler avstand mellom to vektorer. De fleste er nok vant med å måle det som kalles den euklidiske avstanden mellom punkter, som i 3 dimensjoner er:
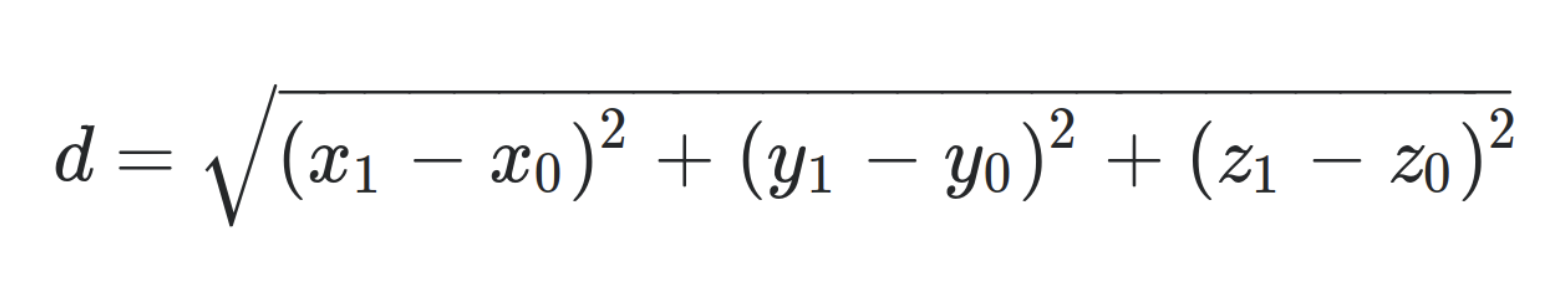
Men i dataanalyse i mange dimensjoner er det mer vanlig å bruke noe som heter cosinus likhet (eng: cosine similarity):
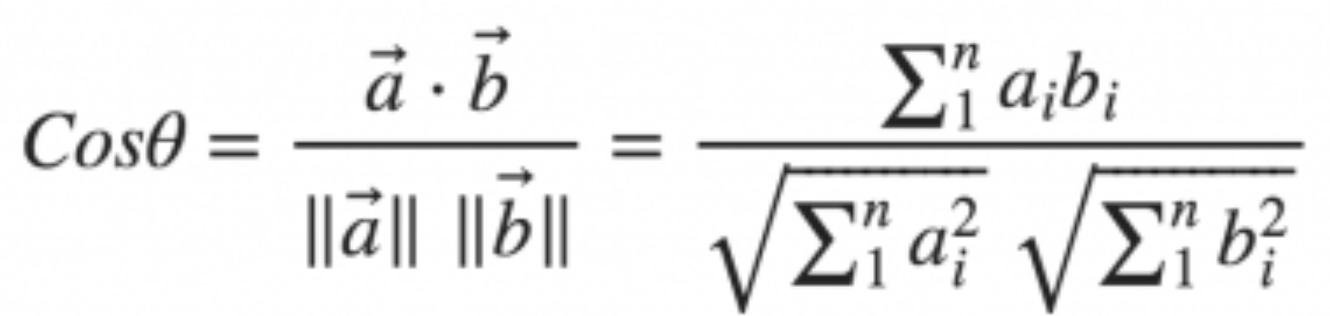
som er et uttrykk for likhet i retning. Denne metoden er ansett som bedre enn euklidisk avstand når man skal sjekke likhet mellom vektorrepresentasjoner av tekster. Cosinus likhet vil alltid være tall mellom -1 og +1, der +1 representerer total likhet, og -1 total ulikhet.
Heldigvis har de fleste vektor-rammeverk innebygget støtte for disse utregningene, så du trenger ikke vite mer enn at det er flere metoder og at det er cosinus likhet du sannsynligvis trenger.
¶Forberede tekst for indeksering
Dataene dine vil nok ligge lagret mange forskjellige steder i mange forskjellige formater. Før du kan søke på disse må de stykkes opp i passe biter og gjøres tilgjengelige via en url eller en eller annen link som gjør at de kan finnes tilbake til.
En passe størrelse kan være alt fra et avsnitt, en side, eller et lite kapittel, men vær klar over at vektoriseringsalgoritmene normalt har en maksimumstørrelse på hvor mye som kan indekseres om gangen. Den modellen vi skal bruke nedenfor klarer noe sånn som 10-30 sider, som bør holde i de fleste sammenhenger. Det er også mulig å først lage et sammendrag hvis man har større dokumenter enn dette.
Her kan og bør det eksperimenteres.
¶Velge vektoriseringsalgoritme
Det er veldig mange vektoriseringsalgoritmer å velge mellom, og de har forskjellige egenskaper. De kan være spesial-trent på visse domener og/eller eller språk og de kan indeksere bilder og video i tillegg til tekst.
Vi har nedenfor valgt å bruke modellen nomic-embed-text. Dette er en moderne modell med et relativt stort kontekstvindu, 8196 tokens, som tilsvarer noe sånn som 10-30 sider. Dette, sammen med at det er enkelt å kjøre modellen lokalt, er hovedgrunnen til valg av denne modellen. Vi kjører den gjennom Ollama, en verktøykasse for bruk av språkmodeller på din lokale maskin. Merk at modellen ikke direkte støtter multi-linguale tekster. Om dine dokumenter er på norsk, bør du nok se etter en annen modell.
Du kan også bruke sky-baserte modeller, så som OpenAI, Antropic m.fl. Disse er generellt ganske kapable, men du må jo sende dataene dine til skyen, og attpåtil betale for det, og det er det jo ikke alle som vil.
Om du har spesielle behov kan det nok være like greit å dykke ned i Python-land og sjekke ut HuggingFace eller Sentence Transformers. Her finner du de siste og beste modellene, som du kan tweake og tune til f.eks. å skjønne ditt eget domene.
¶Kode
Ok, nok prat. Hvordan gjør man så dette i praksis da?
Tekst-vektorer med PostgreSQL
PostgreSQL har en super utvidelse for vektordatabase kalt pgvector. Denne har støtte for å lage multidimensionale vektorer, samt bl.a. å finne nærliggende vektorer ved søk.
Pgvector installerer du først med feks homebrew: brew install pgvector og deretter med:
CREATE EXTENSION vector;
Deretter lager du en tabell som inneholder vektoren sammen med en link til dataene dine:
CREATE TABLE embedded_data (
id SERIAL PRIMARY KEY,
caption varchar, -- nyttig å vise frem sammen med et søkeresultat
resource_link varchar, -- link til kilden
embedding vector(768), -- nomic-embed-text bruker 768 dimensjoner, OpenAI embeddings bruker 1536 dimensjoner
content text -- nyttig for raskere fremhenting i forb. med RAG
-- rettigheter mmm
);
Viktig å legge merke til her er dimensjonen på vektoren. Merk at den må samsvare med dimensjonen din vektoriseringsalgoritme bruker. For Ollama nomic-embed-text er den 768, for OpenAI embeddings er den 1536.
Det kan også være hensiktsmessig å lagre teksten her direkte hvis du vil ha raskere fremhenting, for eksempel om du vil bruke disse i en RAG.
Forberede indeks for søking
For å søke effektivt på vektorer med pgvector må man lage en indeks på embedding-kolonnen. Her finnes det to algoritmer, HNSW og IVFFlat. Grovt sett er HNSW kjappere og gir mer eksakte svar, men er mer memory-krevende, mens IVFFlat kan brukes hvis man har store indekser og ikke så mye minne. Vi går for HNSW. Vi må også angi hvordan vi skal regne ut avstand mellom vektorer, her velger vi cosinus likhet som angitt tidligere.
CREATE INDEX ON embedded_data USING hnsw (
embedding vector_cosine_ops
);
Indeksere dokument-utdrag
Da er det bare å starte indekseringen.
Jeg har valgt å indeksere tilfeldige artikler fra wikipedia, bare for å vise hvordan dette kan gjøres.
Du kan få tak i en tilfeldig jsonifisert artikkel fra wikipedia ved å bruke url-en:
Så algoritmen vår er som følger:
- Hent en tilfeldig artikkel fra wikipedia
- Lag en vektor (embedding) fra teksten
- Lagre vektoren sammen med en link til artikkelen i databasen
- Gå til 1 om du vil vektorisere flere artikler
Jeg har laget et fungerende eksempel på https://github.com/trygvea/embeddings-node, så jeg viser bare de viktigste delene her.
Lage en vektor/embedding gitt en tekst via Ollama
// We use Ollama's API to get embeddings.
const embeddingUrl = "http://localhost:11434/api/embeddings";
// The `nomic-embed-text` model is considered a high-performing open embedding
// model with a large token context window (8196 tokens or 10-30 pages of text).
// See https://ollama.com/library/nomic-embed-text
const model = "nomic-embed-text";
export const createEmbedding = async (prompt: string): Promise<number[]> => {
return fetch(embeddingUrl, {
method: "POST",
body: JSON.stringify({ model, prompt }),
})
.then((response) => response.json())
.then((data) => data.embedding);
};
Lagre vektoren i databasen. Vi bruker modulen “pg” for å snakke med postgres.
...
const client = await pool.connect();
const insertEmbedding = async ({ title, fullurl, extract }: WikiData, embedding: number[]) => {
const query = `
INSERT INTO embedded_data (
caption,
resource_link,
embedding,
content
)
VALUES ($1, $2, $3, $4)
RETURNING *;
`;
try {
const values = [title, fullurl, JSON.stringify(embedding), extract];
await client.query(query, values);
} finally {
client.release();
}
};
Så om vi kjører denne koden for noen artikler, så har vi en database vi kan søke i.
Søke i vektordatabasen
Det som gjenstår er å finne data som matcher et søk. Dette gjøres ved å finne nærmeste naboer til en gitt vektor.
export const searchEmbedding = async (embedding: number[]) => {
const client = await pool.connect();
const query = `
SELECT
resource_link,
caption,
embedding <=> $1 AS cosine_distance
FROM embedded_data
ORDER BY cosine_distance
LIMIT 10
`;
try {
const result = await client.query(query, [JSON.stringify(embedding)]);
console.log("Search Results:", result.rows);
} finally {
client.release();
}
};
Merk bruk av operatoren <=> som brukes når man vil sammenligne vektorer med cosinus avstand.
Merk også at pgvector bruker cosinus avstand som ikke er helt det samme som cosinus likhet beskrevet tidligere – pgvector ser ut til å bruke Cosinus avstand = (1 - cosinus likhet) / 2, så jo mindre tall, jo mer likhet.
På mine 1000 tilfeldige wikipedia-artikler får jeg da disse treffene på søket “Rock artist”:
Searching for content: Rock artist
Search Results: [
{
resource_link: 'https://en.wikipedia.org/wiki/Dark_Horse_%E2%80%93_A_Live_Collection',
caption: 'Dark Horse – A Live Collection',
cosine_distance: 0.39703900903717815
},
{
resource_link: 'https://en.wikipedia.org/wiki/Phil_Stack',
caption: 'Phil Stack',
cosine_distance: 0.4036332663110951
},
{
resource_link: 'https://en.wikipedia.org/wiki/Russell_B_Jackson',
caption: 'Russell B Jackson',
cosine_distance: 0.4270296447349413
}
...
]
Sjekk ut hele koden på https://github.com/trygvea/embeddings-node.
¶Oppsummering
Å implementere vektorsøk er i prinsippet ikke vanskelig. Og når du først har laget vektorsøk så er veien til RAG kort. Det er bare å fylle kontekstet til språkmodellen med de beste treffene i søket.
Så du har egentlig ingen unnskyldning til ikke å prøve. Det er bare å komme i gang. Lykke til!
