Advent of Code er en programmeringskonkurranse som jeg pleier å kose meg med hver desember. Hver morgen fra 1. til 25. desember dukker det opp en ny programmeringsoppgave som du skal løse. Om du klarer dagens oppgave, kommer du videre til del to av oppgaven – en forlengelse av den du nettopp løste. Målet er naturlig nok å løse alle 50 oppgavene og redde julen. Som en person som både liker puslespill og algoritmer, er dette både moro og litt hjernetrim i samme slengen – selv om det at de kommer ut klokka 6 på morgenen er litt vel tidlig for min del.
Selvfølgelig har Advent of Code også et konkurranseaspekt, og du kan lage en privat resultattavle du kan dele med venner eller medarbeidere. Eller, hvis du virkelig har lyst til å utfordre deg mot alle andre i verden, så kan du prøve å komme på den globale ledertavla. Og allerede etter de første dagene var det mange som syntes det var noe som skurret sammenlignet med tidligere år.
For det første var det en bråte med nye folk på ledertavlene. Det er alltid noen nye stjerner som klarer å komme seg inn, men det er alltid en haug med gode gjengangere i toppen år etter år. Nå slet de med å i det hele tatt komme seg inn på den. Den andre tingen som er kanskje mer tydelig var at tidene til de beste var utrolig mye lavere enn tidligere år. Ta for eksempel dag 19: Her har alle de 100 beste klart begge deler av oppgaven på maks 3 minutter. Den beste klarte begge deler på 25 sekunder. Hva er det som har skjedd det siste året?
¶LLMer har tatt over ledertavla… nesten
Som de fleste kanskje allerede har gjettet er dette det første året LLMer har vært såpass gode at de slår oss mennesker på å lese og skrive Advent of Code-oppgaver. Om de ikke løser oppgaven med en gang, har de kanskje skjønt såpass mye at forsøk to eller tre blir riktig.
Dette skaper jo mildt sagt litt rabalder. Primært er folk irritert over at folk forurenser ledertavla med LLMer og ikke mennesker: Advent of Code sier eksplisitt at man ikke skal bruke LLMer for å komme seg opp på ledertavla, men folk gjør det likevel. Den uoffisielle spørreundersøkelsen viser at majoriteten hverken bruker AI selv eller liker at andre bruker det.
Personlig bryr jeg meg ikke så veldig mye om dette for min egen del. Det påvirker ikke min mulighet til å delta eller bruke hjernen, så den eneste måten jeg ser forandring er at min rangering er mye dårligere i år enn den har vært tidligere. Men at LLMer gjør det såpass bra har fått meg til å tenke litt.
For selv om de gjør det veldig bra på veldig mange av oppgavene, kollapser de totalt på de mer kreative eller kompliserte oppgavene. På dag 14 skulle du for eksempel finne ut når en haug med robotstøvsugere dannet et bilde av et juletre, og ingen LLM var tydeligvis forberedt på å tenke på hva i alle dager det betyr eller hvordan man går fram for å gjøre noe sånt.
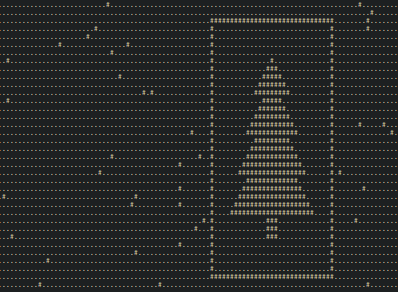
Det var også et par andre dager der LLMene ikke var i nærheten av å løse oppgavene. Den ene kategorien av disse var oppgaver som krevde at du manuelt inspiserte inputet du fikk inn (en noe uvanlig ting å gjøre for programmeringsoppgaver), og den andre kategorien var bare mye mer kompliserte oppgaver enn de andre. Men alt i alt vil du klare å løse 20-21 oppgaver kun ved å spørre en eller annen språkmodell om de kan løse oppgaven for deg, noe som er veldig mange.
¶Et viktig definisjonsspørsmål
Om jeg skulle prøve å skape så mye engasjement som over hodet mulig på sosiale medier kunne jeg skrevet en av disse innleggene:
- I år var oppgavene mye lettere enn tidligere og er veldig like eksisterende problemer. Følgelig er det også enkelt for et oppslagsverk som ChatGPT å slå opp riktig løsningsforslag og skru bittelitt på det.
- Det er imponerende at ChatGPT klarer såpass mange oppgaver uten å ha sett dem før. Det kommer av at de nye modellene kan nå resonnere, og følgelig er vi et bitte lite steg unna kunstig generell intelligens (også kjent som “artificial general intelligence” - AGI).
Den første setningen i begge er riktig, men det er den siste som skaper hete debatter i kommentarfeltet. For ingen av de to er helt riktige, til tross for at det er mange som tror på det ene eller det andre.
Det er spesifikt resonneringsargumentet jeg syntes at folk ofte kaster ut uten å egentlig reflektere over det. I blogposten som kom ut da OpenAI lanserte o1, “Learning to reason with LLMs”, bruker de ordet resonnering igjen og igjen uten å egentlig definere det. Og det er nok taktisk.
Resonnering, i alle fall tiltenkt konteksten brukt i artikkelen over, er definert i Store Norske Leksikon som:
tenkning som innebærer at man trekker […] logiske slutninger fra premisser til konklusjon
Spørsmålet som jeg ikke ser folk spør seg er hvorvidt man kan kalle en sekvens med kall til en statistisk språkmodell for resonnering. Det er helt klart ikke logisk resonnering, men ikke all resonnering er nødvendigvis logisk. Her strides visstnok de lærde, og det er ikke egentlig noen konsensus så vidt jeg har skjønt.
Dette virker kanskje som filosofisk flisespikkeri og kverulering rundt definisjonen av ordet “resonnere”, men jeg mener det er viktig å være klar over det hvis man ønsker å bruke disse modellene. For selv om OpenAI sier at o1 kan resonnere, er det altså fremdeles ingen generell logisk resonnering som skjer. o1 er sikkert koblet til et eksternt verktøy som gjør at den kan detektere og gjøre enkel matte, men den har ikke noen intern modell for generelle fakta. Om det virker som den kan resonnere, ligger det mest sannsynlig på en eller annen måte i treningssettet.
¶Uvanlige spørsmål gir ukorrekte svar
Som Eric Wastl, skaperen av Advent of Code, skriver jeg også programmeringsoppgaver på fritiden. De jeg lager blir med i programmeringskonkurransen IDI Open, som har samme format som ICPC-konkurranser (“NM i programmering” er en av dem). Oppgavene i disse konkurransene er relativt sett vanskeligere enn Advent of Code-oppgaver, i alle fall for mennesker. Men mine er på langt nær vanskelige for ekspertene i programmeringskonkurranser, selv om de krever en god del logisk resonnering. De krever som regel at du gjør noen ukonvensjonelle endringer i en datastruktur eller algoritme, noe jeg ikke har sett i lignende oppgaver. Og hvor vanskelige er de for o1? Tydeligvis veldig vanskelige, for den klarer nesten ingen av dem. Den sliter faktisk med å skrive kode som fungerer på eksempelinputet, og ender oftest opp med feil svar eller programkrasj.
Dette har forøvrig lite med vanskelighetsgraden til oppgavene å gjøre: Som sagt er de relativt sett vanskelige, men det finnes langt vanskeligere oppgaver som o1 klarer å løse uten problemer. Hvorfor det er sånn kan jeg naturlig nok ikke være helt sikker på – mesteparten av hvordan o1 fungerer er jo tross alt en forretningshemmelighet.
Men jeg kan ta et gjett: I all hovedsak handler det nok om at få eller ingen løsninger på disse problemene (eller tilsvarende) er tilgjengelig i treningsdataene. IDI Open er en liten konkurranse og løsningsforslaget er av tilfeldige grunner ikke på nett. Om vi antar at o1 bruker en LLM internt, hjelper det ikke å kontinuerlig prøve å finne en bedre løsning ved å generere mer tekst fra modellen, om ikke løsningen er der.
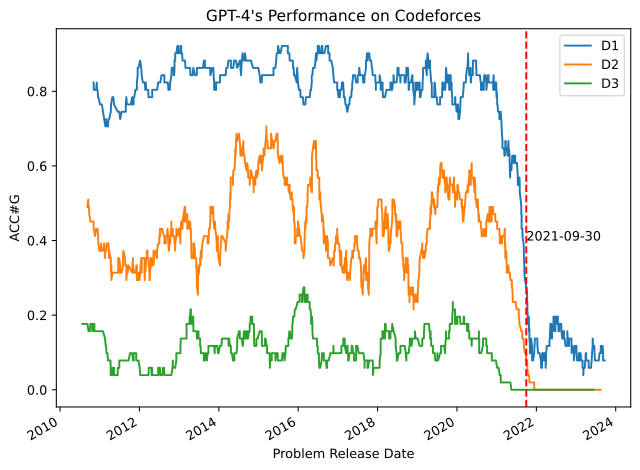
Og selv om løsningen er der, må den også være tilgjengelig på et eller annet vis! OpenAI skryter godt av at o1 klarer å løse mange programmeringsoppgaver. På Codeforces – en nettside med en haug med programmeringskonkurranser – påstår de at o1 nesten er i topp 10% av de beste som er registrert på siden. Om ikke løsningene på disse oppgavene er i treningsdataene er det veldig imponerende.
Men denne imponerende bragden faller veldig fort sammen om du legger inn et par ord i forespørselen du sender til o1. Jeg har spurt o1 om å lage en løsninger ved å spørre den
You are an expert competitive programmer, and you need to solve the problem provided. Return a solution, you do not need to explain it. The problem follows:
<problem her>
og når jeg gjør det får jeg som regel et godt svar tilbake i Python 3, av og til C++. Men om jeg endrer forespørselen til dette
You are an expert competitive programmer, and you need to solve the problem provided. Return a solution in the programming language Common Lisp, you do not need to explain it. The problem follows:
<problem her>
blir det skikkelig kaos. o1 sliter nå stort, og faller sikkert ned til de nederste 10% av brukerne på Codeforces sortert på rangering. Den henter inn ikke-eksisterende biblioteker, og selv med spesifikke beskjeder som “bruk kun standardbiblioteket” tar den i bruk ting som ikke finnes. Jeg tok den til og med i å legge inn 4 uttrykk i en if-setning, dvs. skrive
(if test
a
b
c)
som førte til at hele programmet fikk en kompileringsfeil. Selv folk som ikke kjenner til Lisp skjønner at en if-setning kan ha maks 2 utfall.
Det er fascinerende at det kan gå så fort nedover. Om et menneske fikk denne oppgaven og ikke kunne Common Lisp fra før, ville de kanskje implementert dette i Python, for så funnet en måte å oversette fra Python til Common Lisp. En kort intro til Common Lisp er så å si alt du trenger, for utenom syntaksen er språket veldig likt Python. Du har samme iterasjonsmåter og samme datastrukturer, så om du ikke bryr deg om idiomatisk kode er oversettingen en rent maskinell oppgave. Likevel går alt i stå om du ber o1 om dette, og det igjen antakeligvis fordi det er få/ingen løsninger på nettopp dette problemet i Common Lisp.
¶Om status quo er treningsdataene, er det lettest å ikke innovere
“Hva så?” tenker en eller annen person der ute, mens de ber en eller annen AI lage enda en React-komponent i TypeScript. Det er jo forståelig at man stiller spørsmålet: Programmeringskonkurranser er jo definitivt ikke det vi gjør på jobb, og de færreste av oss programmerer i Common Lisp. Men det finnes en lignende parallell her i utviklingsverden.
La oss si at det er noen som har funnet opp enda et nytt frontendrammeverk, og denne gangen er det faktisk bedre enn React eller hva enn du bruker. Du skriver halvparten så mye kode og produserer halvparten så mange bugs… om du skriver koden selv. For det å bruke AI-verktøy med dette rammeverket er bare ren frustrasjon: Den produserer en haug med bugs og ikke-fungerende kode. Det skjer fordi rammeverket er så nytt at det ikke finnes i treningsdataene, det er lite eksempler ute på nett, og det er ikke likt nok til at AIen klarer å benytte seg av kunnskapen fra lignende rammeverk.
Til en viss grad er det greit med litt friksjon når det kommer til nye verktøy. Det har en kost, og vi trenger ikke bytte ut frontendrammeverket vi bruker annenhver uke. Men friksjonen bør være i det å bytte ut gamle verktøy med nye, ikke rundt det å teste og eksperimentere med dem på prototyper eller nye prosjekter. For det er allerede mye friksjon rundt det å teste verktøy som er annerledes enn det man er vant med: Bare spør de som har lært seg å programmere i Haskell eller Clojure. Du føler deg treg og lite produktiv i starten, og du er frustrert over verktøyoppsettet. Denne følelsen vil nok bli enda verre om du er vant til at AI hjelper deg med å autogenerere kode, og du ikke har tilgang til en.
Det vil definitivt ikke stoppe nye rammeverk fra å komme ut, ei heller vil det forhindre nye språk fra å bli laget. Men jeg tror det blir mindre sannsynlig for at de blir populære, spesielt for de som ikke har store bedrifter i ryggen. Og det igjen er litt skummelt, for store bedrifter har ikke de samme problemene som mindre bedrifter har.
¶AGI vil ikke skje via AI-by-learning
“Men hva med o3? Den slår mennesker i en haug med ytelsesmålinger! Den er kun dårligere enn 178 personer i verden i programmeringskonkurranser!” er det kanskje noen ekstremt optimistiske personer der ute som sier. Og joda, i en videopresentasjon (her tekstlig oversatt) forteller folka i OpenAI at o3 slår mennesker i mange vanskelige oppgavesett, både i matte og programmering.
Men det begynner å bli vanskelig å forstå hva vi egentlig måler på dette tidspunktet. Når det kommer til Codeforces-rangeringen synes jeg den alltid har vært litt vanskelig å kommentere på, da alle oppgavene er ute og tilgjengelig. Lager modellen løsninger via resonnering, eller kopierer den noe den fant fra GitHub? ChatGPT 4 har dette problemet, der kvaliteten på løsningene faller som en stein det øyeblikket oppgaven ikke lenger er i treningssettet. Kanskje o1 og o3 har samme problem, kanskje ikke – det er ikke tydelig ut fra bloggposten, og vi må nok vente litt før vi vet svaret på det.
Og selv om man skulle tro de private oppgavesettene kan gi en bedre pekepin på hvor god en AI-modell er, så er det jo litt rart å si at en proprietær AI er bedre som kodeassistent fordi den rangerer høyere på et sett med oppgaver vi ikke selv kan se, ei heller aldri vil selv prøve å løse. Som vår venn som genererte React-komponenter via AI litt tidligere sa, “Hva så?” om den klarer å løse en haug med vanskelige programmerings- og matteoppgaver?
For en vanlig bruker er det jo heller enklere oppgaver vi ønsker å bruke AI på. Mesteparten av oss lager CRUD-applikasjoner, og om man får en AI som klarer oppgavene våre i 85% av tilfellene, må vi fremdeles passe på den. Om den stiger til 90% er det bra om det ikke koster alt for mye, men den store revolusjonen vil jo ikke skje før den gjør mindre feil enn en gjennomsnittlig programmerer.
Jeg vil tro OpenAI og en haug andre ser på disse som en slags indirekte måling på hvor godt AIen klarer å resonnere logisk, dvs. hvor god den er. Men som nevnt tidligere, så er ikke dette logisk resonnering om den utfører en sekvens med kall til en statistisk språkmodell – kun en imitasjon av logisk resonnering. Og en imitasjon av X vil ikke oppføre seg på samme måte som X: Det er ikke nødvendigvis slik at en AI med gode ferdigheter i programmeringskonkurranser er god på å kode apper. Selv for oss mennesker er dette en dårlig parallell: Jeg klarer å løse vanskelige programmeringsnøtter, men det hjelper meg særdeles lite med apputvikling, og jeg vil tro dette også gjelder for en LLM-basert AI.
“Men en god nok imitasjon vil ende opp med å virke identisk med et veldig smart menneske!” er det mange som tenker. Så lenge vi sper på med mer data og mer beregningskraft, så får vi noe som til slutt er det samme som menneskelig resonnering – eller kanskje enda bedre. Og det er faktisk riktig, men i praksis umulig. AI-by-learning er nemlig NP-hardt: Å få til en lineær forbedring krever eksponensielt mye mer data og beregningskraft.
Å forklare beviset i forskningsartikkelen “Reclaiming AI as a theoretical tool for cognitive science” er nok litt vel i overkant mye i en allerede lang bloggpost. Men veldig enkelt forklart tar forfatterne og beviser at man kan løse et problem X ved å lage en algoritme som benytter seg av AI-by-learning. Og man vet allerede at X er NP-hardt, derfor vil det være en selvmotsigelse hvis AI-by-learning er løsbart i polynomisk tid.
Dette er antakeligvis tilfellet for o1, og OpenAI har vært snille nok til å gi oss data som underbygger det. Som du ser i grafen under er x-aksen logaritmisk, som betyr at forbedringene tar eksponensielt lengre og lengre tid.
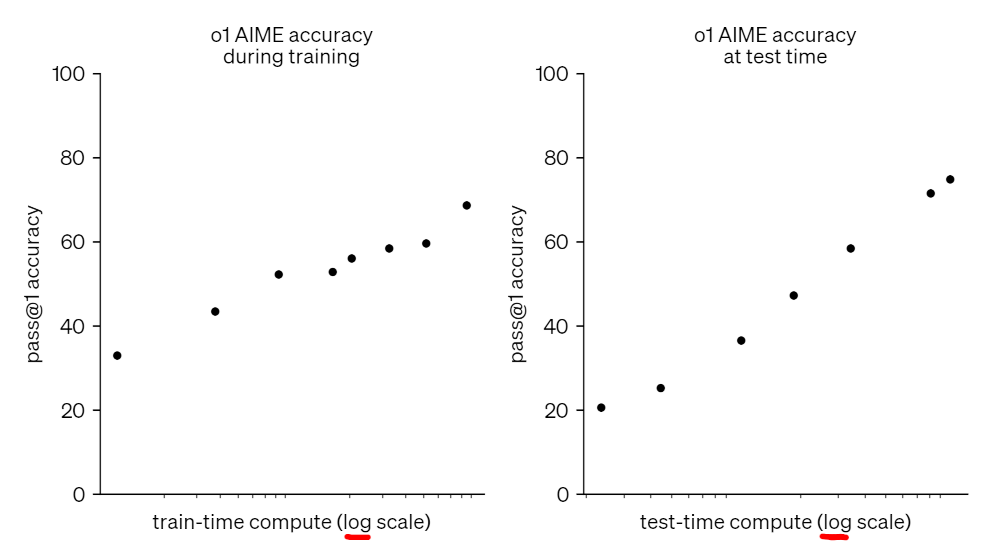
I praksis vil det bety at vi på et eller annet tidspunkt ikke får noen gevinst av å pøse på mer data eller regnekraft for å lage disse modellene som kun bruker læring. For å komme videre må vi heller lage nye algoritmer som bruker dataene bedre, og for å kunne få til AGI må vi bruke noe som ikke primært bruker maskinlæring til å resonnere.
¶AI trenger ikke være AGI for å være nyttig
Som du skjønner er jeg litt oppgitt over alle som snakker som om AGI kommer i løpet av de neste 2-3 årene. For det første er ikke dagens progresjon en indikasjon på at vi kommer dit i det hele tatt. Det kan godt hende at vi finner opp noen algoritmer i løpet av de neste årene som endrer det, men som sagt vil ikke de være primært maskinlæringsbaserte. Og det vil være en radikal endring i hvordan AI blir laget sammenlignet med dagens modeller.
For det andre er dagens AI-modeller allerede nyttige. Ikke perfekte – som jeg viste tidligere er de faktisk forferdelig dårlige i Common Lisp og det å finne ASCII-juletrær. Men de er gode nok til at vi noen steder kan ta de i bruk som et verktøy, gitt at vi ser over svarene først.
Om vi bør er en annen sak. I denne bloggposten har jeg holdt meg helt unna de etiske problemstillingene med AI: Er det OK at de soper inn en haug med data, uavhengig av opphavsrett? Er det OK at vi bruker såpass mye vann og energi på disse tingene? Og skal vi fortsette å bruke mye vann og energi på å lage mer og mer sofistikerte modeller? Om svaret på sistnevnte er ja fordi vi håper det gir oss AGI, er det greit med en liten realitetssjekk først.
