En ting jeg kontinuerlig prøver å ha i bakhodet når jeg designer systemer, er
tingene jeg liker med de verktøyene jeg selv bruker. Ikke helt på detaljnivå –
at jeg liker map-funksjonen over for-løkker hjelper meg lite – men snarere
fellesnevneren mellom mange ting jeg setter pris på.
Grunnen til at jeg gjør det er enkel: Jeg føler at mange IT-systemer jeg interagerer med ikke bruker alle triksene som gjør oss mer produktive når vi programmerer. Det er jo litt forståelig – mediumet vi bruker for å lage IT-systemer er nesten alltid ren tekst, og det har en haug med fordeler som vi ikke alltid kan anvende for domenelogikk. Men samtidig tror jeg vi har lagt litt vel mye inn i skuffen, uten å evaluere hvor vanskelig det er å implementere den funksjonaliteten for kundene våre. Heldigvis er det også en god del ting vi bruker, så la oss ta en titt både på det vi aktivt tar i bruk fra verktøyskuffen, samt det jeg ønsker å se mer av.
¶Tilbakemelding når jeg ønsker det
Kanskje det enkleste og mest tydelige eksempelet på ting jeg verdsetter er rask feedback. Dette kan komme i mange varianter når jeg programmerer: Fra nettsider som oppdaterer seg øyeblikkelig når jeg lagrer endringer i CSS eller kode, til raske feilmeldinger fra kompilatorer eller enhetstester som kjører det øyeblikket jeg lagrer en fil. Gjerne ønsker jeg tilbakemelding så fort jeg har gjort en endring, og vil verifisere at den ikke har skapt noe krøll.
Og her har IT-systemer i dag ikke egentlig noen problemer. Vi gir rask tilbakemelding når noe går bra eller galt, og vi er klar over at spinnere og “vennligst vent”-meldinger helst bør være unntaket. Men noen sider kan faktisk bli litt vel overivrige.
Ta for eksempel en innloggingsside som validerer at eposten du skriver inn er korrekt. Du ønsker ikke at den validerer det du skriver inn ved hvert eneste tastetrykk, for det blir jo bare en distraksjon:

Men når skal man da gi tilbakemelding? Vel, når jeg er ferdig med å skrive og klar for å motta tilbakemeldingen så klart! Og her er det to naturlige steder å tenke at brukeren er ferdig og klar for feedback: Når man er ferdig med å fylle inn feltet, eller når man trykker på “send”-knappen (eller hva enn det står på den).
De lærde strides om hva som er best UX-messig. Sånn som når vi utviklere trykker hurtigkommandoen for å lagre en fil, tenker jeg at det som regel er ok å vente til brukeren trykker på “send”-knappen. Men da bør også alle feltene være synlig på skjermen, og om det ikke er mulig, bør man helst dele opp skjemaet over flere sider. På den måten unngår du at brukeren får feil i et felt som ikke lenger er synlig på skjermen.
¶Automatiske forslag er kjekke saker
Vi mennesker er late skapninger, og det å fylle inn ting manuelt holder vi oss unna så langt det lar seg gjøre. Å bruke tab for å få editoren din til å automatisk skrive ferdig et metodenavn er følgelig noe de fleste utviklere er godt kjent med. Kanskje du til og med har en IDE som har direkte tilgang til SQL-databasen din og kan foreslå fornuftige joins basert på hvilke tabeller og kolonner de tabellene har.
Vi er også gode til å dele dette med brukerne av IT-systemene vi lager, på mange
forskjellige måter. Den absolutt enkleste måten å få automatisk utfylling på er
via
autocomplete-attributen
som man kan plassere på HTML input-elementer. Den fyller enten ut ting
automatisk, eller gir deg forslag på hva du skal skrive inn i inputfeltet du har
foran deg. Typisk vil du se dette på nettbutikker som trenger informasjon om
navn og adresse for å sende pakken til postkassen din.
Men her kan man være langt mer kreativ: Si du lager et avvikssystem for fabrikker med mange maskiner. I stedet for at kontrolløren må skrive inn et langt serienummer når de finner et avvik, kan du heller be dem skanne en QR-kode klistret på maskinen. Og bønder i Norge har dyr med RFID-øremerker, så om brukerne har en RFID-leser kan du gjøre registreringsarbeid enda raskere om du implementerer støtte for det.
Selv om QR-koder og RFID-brikker gir ut eksakt informasjon, trenger ikke uthenting av data være 100% korrekt for at det skal skape verdi. Om det fungerer i 50-70% av tilfellene kan det fremdeles ha en netto gevinst, for det å skrive inn tall og data tar som regel mye tid.
Jeg ser det kanskje mest tydelig når jeg skal levere utlegg i Tripletex. Der må jeg uansett laste opp kvitteringer, og veldig ofte klarer systemet å hente ut de riktige tallene med riktig valuta, som sparer meg for en god del tastearbeid. Man må jo selvfølgelig dobbeltsjekke tallene, men det er ofte en smal sak.
Og når det kommer til uthenting av data som ikke nødvendigvis er 100% korrekt, kommer man ikke unna det å diskutere AI og LLMer. Copilot og Cursor AI er jo verktøy som har tatt utviklermiljøet med storm. I praksis er de autocomplete på steroider, men med litt varierende kvalitet – Alf Kristian skrev nylig om hvor varierende det kan være. Likevel tror jeg bedrifter har litt å hente her: Om en bruker trenger å skrive ned data fra dokumenter som ikke følger en forutsigbar struktur, kan en AI-integrasjon antakeligvis hjelpe stort med å hente ut en god del av den dataen. Brukerne må nok filtrere seg gjennom en god del feil, men det kan hende det er bedre i snitt enn å fylle ut dataene selv.
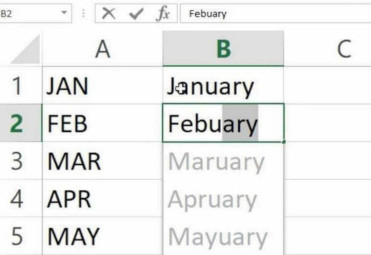
Da det er sagt bør du nok gjøre en god del testing før du bare integrerer noe AI inn i programmet ditt og dytter det ut på brukerne. Opplevelsen for brukerne kan bli skikkelig dårlig om man gang på gang må fikse opp i ting AIen foreslår, men som virker selvsigende for oss mennesker. Og selv om man sier at dette er gjort av en tredjeparts AI, vil nok folk assosiere den dårlige opplevelsen med produktet ditt uansett hvordan man snur og vender på det.
¶Historikk og tidsreiser mangler vi
Når jeg tenker på UX-design er Git et verktøy jeg ofte kommer tilbake til. Tross kompleksiteten til Git, er versjonskontroll som konsept essensielt i dagens utviklingsmiljø. Det gir oss muligheten til å se på historikken til en fil, se på hvordan koden så ut bakover i tid, og gjør at flere kan jobbe samtidig på en og samme ting uten at vi spenner for mye bein på hverandre. Men utenom enkel historikk og hendelseslogger, er dette funksjonalitet jeg i praksis aldri ser utenfor programmeringsverktøy.
Jeg tror nok ikke det er tilfeldig: Med mindre du bruker Datomic er det krøkkete å modellere historikk, og spørringer for å hente ut data slik databasen så ut tilbake i tid krever at du holder tunga rett i munnen. Det å vise endringer er også vanskelig. For ren tekst er en “før/etter”-visning greit, men for domenespesifikke objekter blir dette ofte noe du må implementere manuelt. Noen ganger kan dette virke vanskelig, for hva som er en endring er ikke alltid enkelt å vite, og er av og til kontekstavhengig.
Ta for eksempel en TODO-liste med noen oppgaver. Vi er alle enige i at TODO-lista har endra seg når en av oppgavene har blitt markert som gjort, men har den endret seg om den ansvarlige for en oppgave ble endret fra Per til Pål? Her kan svaret både være ja og nei.
Selv om det virker vanskelig å implementere det ved første øyekast, tror jeg vi overestimerer kompleksiteten – gitt at vi bruker de riktige verktøyene – og underestimerer verdien det gir. For hvem av oss utviklere ville gått tilbake til en verden uten versjonskontroll?
¶Debuggere til folket?
Det er klart at noen verktøy blir litt vel urealistiske å dele med brukerne. Debuggere er et slikt eksempel. Teknisk er det jo opplagt hvorfor: Det er alt for tidkrevende å implementere, og det å lære opp brukerne våre i hvordan man bruker en debugger er dårlig bruk av tid for alle. For selv om vi har mange gode ting i verktøykassa, er ikke alle like godt egnet utenfor programmeringsverden.
Men det vi bruker en debugger til kan vi ta lærdom av: Vi bruker debuggere til å forstå hvorfor programmet vårt ikke fungerer som det skal. Så om vi ikke kan gi brukerne våre en debugger, må vi sørge for at debuggere ikke er nødvendig for brukerne våre; systemet må være lett å forstå. Det er mange måter å komme dit, men jeg vil belyse to teknikker. Den første handler om å gjøre ting såpass enkle at det er trivielt å forstå hva som skjer. Konseptuelt enkelt, men ofte vanskelig å få til i praksis. Og når det ikke er mulig kan du kanskje lage en hendelseslogg som forklarer de forskjellige stegene og valgene som skjedde internt i systemet.
Si for eksempel at en bruker lagrer noe data som også må sendes over til et eller annet register. Om noe går galt med overføringen er det greit for brukeren å kunne se en tidslinje med hva som skjedde når, og hva feilmeldingen fra registeret sier. Kanskje feilmeldingen har et litt forenklet språk, men jeg syntes det likefult bør være en melding som går litt i detalj. For brukerne våre er ikke dumme. De kan google og lære seg ting, og av og til forstår de hva som har gått galt og finner en midlertidig løsning på problemet. Det er vanskelig når du ikke vet hva som skjer under panseret.
Som du ser er det mye vi kan stjele fra verktøyene våre. Jeg håper du har blitt inspirert til å tenke mer på hva som gjør programmeringshverdagen din god, og hva du kan ta med deg videre til brukerne dine. For det er mange gode idéer og konsepter i programmeringsverktøy, og det ville vært trist om bare programmerere får glede av dem.
