Når folk anbefaler deg å lære deg et nytt programmeringsspråk, er argumentet som regel en av disse to:
- Du kommer lettere inn på nye prosjekter der det brukes
- Du lærer nye programmeringskonsepter som gjør deg til en bedre utvikler
Det første argumentet er selvforklarende: Om du ikke kan et frontendspråk, blir det vanskelig å finne jobb som en frontend- eller fullstackutvikler. Og om det eneste du kan er Cobol og Smalltalk, blir det vanskelig å komme seg inn på prosjekter som bruker Java eller C#.
¶Stjel konsepter og ideer
Det andre argumentet handler mer om å forstå alternativene til programmeringskonsepter i språkene du allerede kan: Om du bruker et språk som har try/catch, prøv et språk som returnerer feil som verdier i stedet. Om du jobber i språk med hovedsakelig mutable datatyper, prøv deg på et språk som bruker immutable datatyper som standard.
Verdien av det er ikke bare intellektuell stimulering, selv om det kan være en stor faktor. Det er mange gode ideer og konsepter i andre språk, og du kan som regel benytte deg av dem i “hverdagsspråkene” dine. Ideene og konseptene vil nok ikke kunne brukes i hele programmet ditt, men en og annen gang finner du en del av kodebasen der det er fornuftig å bruke det – framfor det som regnes som “best practice”.
¶Men ikke begrens deg til bare språket!
Jeg synes mange fokuserer litt mye på selve språket. Selv om det er superstjerna, er det også veldig mye du kan lære av verktøyene du bruker og økosystemet rundt språket.
Ta for eksempel Go. Om du skal bygge et Go-program trenger du som oftest bare å
installere Go lokalt, kjøre go build i rotmappa til programmet, og så har du
et program du kan kjøre lokalt. Legg til noen ekstra argumenter på den
byggekommandoen, og du har et program du kan kopiere og kjøre på hvilken som
helst Linuxserver (eller i helt tomme Dockerbilder).
Eller hva med Clojure: I Clojure har du REPLet tilgjengelig i et kjørende program, og du kan evaluere både store og små kodesnutter rett i det kjørende programmet. Det gjør at utviklingsflyten gir deg mye raskere tilbakemelding enn testing/rekompilering og restart av hele programmet, og du kan “leke deg” fram til riktig måte å implementere en funksjon på. Når du er fornøyd kompilerer du endepunktet ditt, og kan teste det rett i nettleseren eller appen din.
¶Små språk har bugs og lite funksjonalitet – og det er bra!
Alt dette er bra, men små språk er også verdifullt å lære seg, selv om de ikke passer inn i de to argumentene nevnt helt øverst i teksten. “Hvorfor?” er jo det naturlige oppfølgingsspørsmålet, og for min del er det fordi biblioteker og verktøy ofte er mer buggy og har mindre funksjonalitet enn de større språkene. Dette virker jo som argumenter for å unngå små og nye programmeringsspråk, så la meg forklare nærmere:
Når vi lager systemer i store språk, som f.eks. Java og JavaScript, bruker vi oftest biblioteker som er testet og brukt av en haug med andre bedrifter. Følgelig er det sjelden store og kritiske bugs i de bibliotekene, og vi trenger ikke være redd for at vi treffer på noe rar moro som vi må grave i. For små språk er jo antall brukere per definisjon mindre, og derfor er biblioteker mindre testet. Heldigvis er det sjelden slik at bibliotekene er dårlige, men nå og da er det et komplisert hjørnetilfelle som ikke er håndtert helt riktig, eller ikke implementert i det hele tatt. Da må du begynne å grave i koden for å skjønne hvor og hvorfor det går galt.
For deg som utvikler er dette en gullgruve av to grunner. For det første blir du god på å grave i biblioteker og kode du ikke er kjent med, og for det andre lærer du om de kompliserte hjørnetilfellene.
Å debugge uten press
I 2018 utfordret jeg meg selv til å løse Advent of Code i en haug ukjente programmeringsspråk, og språket Myrrdin ble valget for dag 4. Inputdataene for den dagen var på følgende format:
[1518-11-01 00:00] Guard #10 begins shift
[1518-11-01 00:05] falls asleep
[1518-11-01 00:25] wakes up
(... flere linjer med samme format)
Jeg tenkte at jeg likesågodt kunne bruke en regex for å hente ut datoen fra
[...]-biten av linja, og la resten være noe jeg kunne bearbeide litt senere i
oppgaven. Følgelig begynte jeg oppgaven sånn her:
var re = std.try(regex.compile("\\[(\\d+)-(\\d+)-(\\d+) (\\d+):(\\d+)\\] (.+)"))
Du har kanskje hørt sitatet fra Jamie Zawinski om regexer:
Some people, when confronted with a problem, think “I know, I’ll use regular expressions.” Now they have two problems.
Dette var det jeg tenkte ca. 2 sekunder etter at jeg prøvde å kjøre første
versjon av programmet mitt, fordi regexen ikke kompilerte ifølge Myrrdins
standardbibliotek. Etter litt graving fant jeg problemet, for den håndterte ikke
\\]-biten av regexen riktig. Biblioteket trodde jeg skulle lukke en []-bit
av en regex, men fant ikke ut av hvor jeg åpnet den, og bestemte seg for å gi ut
en litt kryptisk feilmelding. Med litt fikling og et par runder med
rekompilering av Myrrdin-kompilatoren, fikk jeg endelig fikset regexproblemet og
dagens Advent of Code-problem.
Alle er enige i at det er verdt å lære seg å lese andres kode, men det er som oftest i egen kodebase det skjer. Av og til graver man jo litt i biblioteker man avhenger av, men det er sjelden kost at dette blir noe annet enn “disse versjonene av bibliotekene spiller ikke helt på lag” eller at du finner en workaround i en GitHub-sak for biblioteket. Litt lengre ned i stakken, under panseret på HTTP-klienten eller regexmotoren, er det få som tar turen frivillig. Det er jo ikke akkurat god sengelektyre, og det er bedre måter å lære seg hvordan de fungerer konseptuelt enn å lese koden.
Så det å debugge disse greiene mens man programmerer er en gylden mulighet, men det skjer som sagt sjelden i store språk: Disse har jo blitt testet ut og inn av en haug med mennesker, og at akkurat du treffer på en bug er minimal. Men det kan skje, og det kan være en kritisk bug for systemet ditt. Og når det skjer, er det greit å ha litt erfaring med hvordan man navigerer slike kodebaser.
Hvem sendte oss den feilkoden, sa du?
Et annet problem i små språk er at funksjonalitet ikke er implementert. Dette skjer som regel av to grunner:
- En utvikler lagde biblioteket for eget bruk, og trenger ikke funksjonaliteten, eller
- Det er komplisert funksjonalitet som er vanskelig å implementere
For hobbyprosjekter er dette helt ok, litt avhengig av motivasjonen din. Du kommer deg ofte overraskende langt med lite funksjonalitet, og enkel funksjonalitet som mangler kan du ofte implementere selv. Litt verre er det med mer komplisert funksjonalitet.
Ta for eksempel noe vi alle tar for gitt: HTTP-klienter som håndterer redirects. For øyeblikket jobber jeg på et hobbyprosjekt i OCaml, og integrerer med Cover Art Archive for å hente ut omslagskunst til album jeg liker. APIet er enkelt å bruke og implementere selv, så lenge du har de riktige IDene til albumene du ønsker. Men du må håndtere redirects, for Cover Art Archive sender deg videre til the Internet Archive om den kjenner igjen IDen.
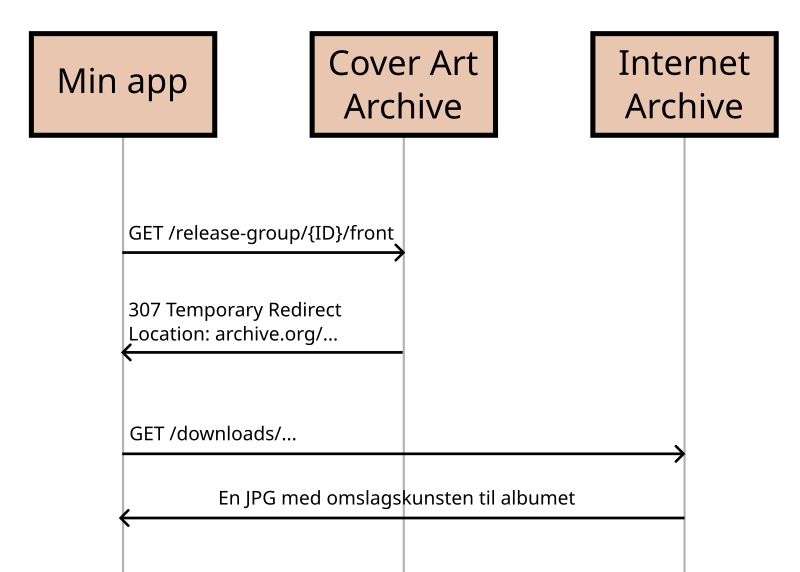
Jeg tenkte dette kom gratis med OCaml-biblioteket Cohttp, men til min overraskelse fikk jeg bare tilbake HTTP-responsen 307 (Temporary Redirect) med lokasjonsdataene når jeg sendte inn forespørsler til Cover Art Archive. Heldigvis var dette godt dokumentert: I readme-fila til Cohttp er det en god forklaring på hvordan du kan implementere det selv, samt en lenke til en litt mer utfyllende forklaring på hvorfor det ikke er gjort i biblioteket. Jeg tok koden, justerte litt på den til mitt behov, og forstod i samme slengen hvorfor dette er vanskelig å håndtere på en god måte for programmerere.
La oss anta at vi har noe kode som ser sånn her ut:
resp := http.post(url, body)
if resp.status == 5xx {
// serverfeil, send inn dataene på nytt
}
Jeg vil tro mange har skrevet kode som ligner dette, men denne har en potensiell
bug. For hva skjer egentlig hvis du får tilbake 303 See Other, følger
lenken, og så får en 503? I de fleste språk vil du kun se 503-en da prøve å
POSTe på nytt, selv om du fikk tilbake 303 som indikerer at selve POSTen gikk
fint. Om APIet ikke er idempotent kan det hende du
ender opp med å duplisere (eller verre!) hva enn du postet.
Tilfeldigvis hadde jeg en lignende situasjon i mitt prosjekt: Cover Art Archive kjører helt fint, men Internet Archive er i skrivende stund nede, og følgelig får jeg en salig blanding av sertifikatfeil, timeouts og statuskoden 503/504. Om Cohttp hadde hatt redirects implementert i biblioteket hadde jeg nok trodd at selve Cover Art Archive var nede, men jeg la opp feilmeldingen til å informere tydelig om hvilken tjeneste det faktisk gikk galt for.
Trenger du egentlig den funksjonaliteten?
Av og til er redirects nødvendig, så tross kompleksiteten den innfører er det et nødvendig onde til tider. Men jeg treffer sjelden på redirects i APIer, og om man ikke trenger det, hva er da egentlig poenget med å ha det skrudd på?
Kompleks funksjonalitet er sjelden så alt-eller-ingenting som det redirects er: Trenger du å laste opp ting til S3 med multipart-uploads? Trenger du egentlig en ORM? Kan et enkelt JSON-API fungere framfor et GraphQL-API? Trenger du egentlig et API i det hele tatt, eller holder det med å bruke ren HTML? Hvor tregt går det egentlig å kjøre på en kjerne? Mye av det er en avveining mellom kompleksitet og noe annet (ytelse, utviklerglede, etc.), og kanskje du velger kompleksitet uten å reflektere på at du har et alternativ.
Med små språk er valget ofte tatt for deg. Kanskje du finner ut at du er like produktiv uten disse standardverktøyene, og kanskje du finner ut hvorfor du virkelig liker å ha andre tilgjengelig.
Og når du virkelig trenger noe, blir du nødt til å implementere det selv: Det er en god måte å finne ut av hvorfor det ikke allerede eksisterer i språket du bruker, og hvor vanskelig det faktisk er. Om det er komplekst, er det også mer sannsynlig at den tilsvarende funksjonaliteten forårsaker bugs på arbeidsplassen din sammenlignet med enklere funksjonalitet. Da er det greit å faktisk ha implementert noe tilsvarende, for når systemet ikke gjør som det skal, er det lettere å vite om denne biten av systemet har skylden eller ei.
¶Først og fremst fordi det er gøy
For bedrifter er nok veldig små og unge språk en stor risiko – i alle fall til å begynne med. Mange av dem er hobbyprosjekter med få utviklere, og de som bidrar til miljøet starter jo først å programmere i det alene. Det kan føre til litt lite dokumentasjon, og biblioteker blir designet primært fordi forfatteren trenger det – ikke nødvendigvis fordi de vil gjøre biblioteket like bra som Java- eller C#-versjonen der ute.
Kombinerer du det med dårlig IDE-støtte, ingen autofullføring og ingen offisielle SDKer fra AWS/Google/Apple osv. blir det trått å skrive i språket.
Men som et verktøy for læring og refleksjon er det genialt, om du er motivert nok til å lage ditt nye hobbyprosjekt i det. Jeg føler meg utrolig heldig sånn sett: Jeg liker å leke med nye språk – både store og små – og har lært mye av det. Både når det kommer til hva jeg faktisk trenger for å bygge et system, og også hvilke biter av systemet som er de mest kompliserte.
Men utviklingshastigheten på de hobbyprosjektene er ikke akkurat noe å skryte av.
