Stort sett bruker vi kanskje bare JVM-språk uten å tenke så mye på hva som skjer under panseret med alle objektene vi ikke lenger har behov for. Automatisert minnehåndtering var også et av salgsargumentene da Java ble lansert. Det forenkler koden og reduserer muligheten for minnelekasjer - en type feil som ofte kan være litt tricky å spore ned. Garbage Collection (GC) har alltid fascinert meg - en superkompleks motor som gjør hverdagen vår mindre komplisert.
Da jeg satte meg inn i de siste Java-versjonene for noen uker siden tenkte jeg det kunne være artig å se litt nærmere på hva som har skjedd på GC-fronten. For 8 år siden skrev jeg en artikkel om å sammenligne forskjellige GC innstillinger. Nå har jeg dratt opp dette arbeidet igjen og sett på hvordan ting ser ut med alt som har skjedd på GC-fronten siden da.
¶GC Oversikt
Det finnes flere ulike implementasjoner av GC i en standard JVM. Her er et forsøk på oversikt over hvilke alternativer man har i de nyeste JVM versjonene:
- Serial GC - En primitiv implementasjon som kun bruker en tråd og stopper applikasjonen din mens den holder på. Har lavt minnebruk så om du tåler små pauser er denne fin for embedded applikasjoner hvor det er begrenset med minne tilgjengelig.
- Parallel GC - Denne stopper også applikasjonen mens den jobber, men bruker flere tråder. Passer for applikasjoner med større datamengder hvor man kan frigjøre raskere vha multithreading. Parallel GC var default implementasjon i JVM til og med Java 8.
- G1 - Dette er default implementasjon i en moderne JVM (fra Java 9). Den gjør deler av jobben parallelt med applikasjonen, og pauser applikasjoner for noen operasjoner. Det vil si at den får kortere og færre pauser enn de to beskrevet over, men kan påvirke ytelsen til appliasjonen siden den legger beslag på tråder som kjører sammen med applikasjonen sine tråder.
- ZGC - Denne implementasjonen er laget for å unngå pauser i applikasjoner med høyt minnebruk. Så om man har ekstremt høye krav til svartid er denne verdt å se på.
- Shenandoah - Denne skal også kjøre uten å lage pauser i applikasjonen din. Den bruker mye CPU og frigjør minne direkte til OS-nivå.
- Epsilon GC - Kalles også no-op GC. Den frigjør ingenting - og er kun ment for bruk i applikasjoner som har en konstant minnebruk.
Her har det skjedd mye i løpet årene som har gått siden Java 8. CMS (Concurrent Mark Sweep) er helt borte fra Java 14 og nyere. Vi har fått 3 helt nye alternativer (ZGC, Shenandoah og Epsilon). Og kanskje størst av alt er en lang rekke stegvise forbedringer på standard-implementasjonen G1. Den har forbedret både throughput, latency og memory footprint. Så rett ut av boksen kan man forvente en god del bedre ytelse bare ved å kjøre på en oppdatert JVM.
¶Hvordan overvåke GC?
Jeg har tatt min gamle test-applikasjon og kjørt med alle dagens GC-alternativer. Loggene har jeg lest med GCViewer slik jeg gjorde da jeg skrev om dette for lenge siden. Finnes sikkert mer moderne verktøy man kan bruke - men det får frem hovedpoenget.
For hver GC har jeg kjørt applikasjonen med full GC-logging til en fil. Maks heap satt til 2 GB - eksempel på Shenandoah:
-Xmx2g -XX:+UseShenandoahGC -Xlog:gc*:file=gc_shenandoah.log
Med GCViewer lastet ned kan man bare kjøre denne rett på log-filen:
java -jar gcviewer.jar logs/gc_zgc.log
Denne åpner da et vindu med en slags graf og noen nøkkeltall. For eksempel for ZGC:
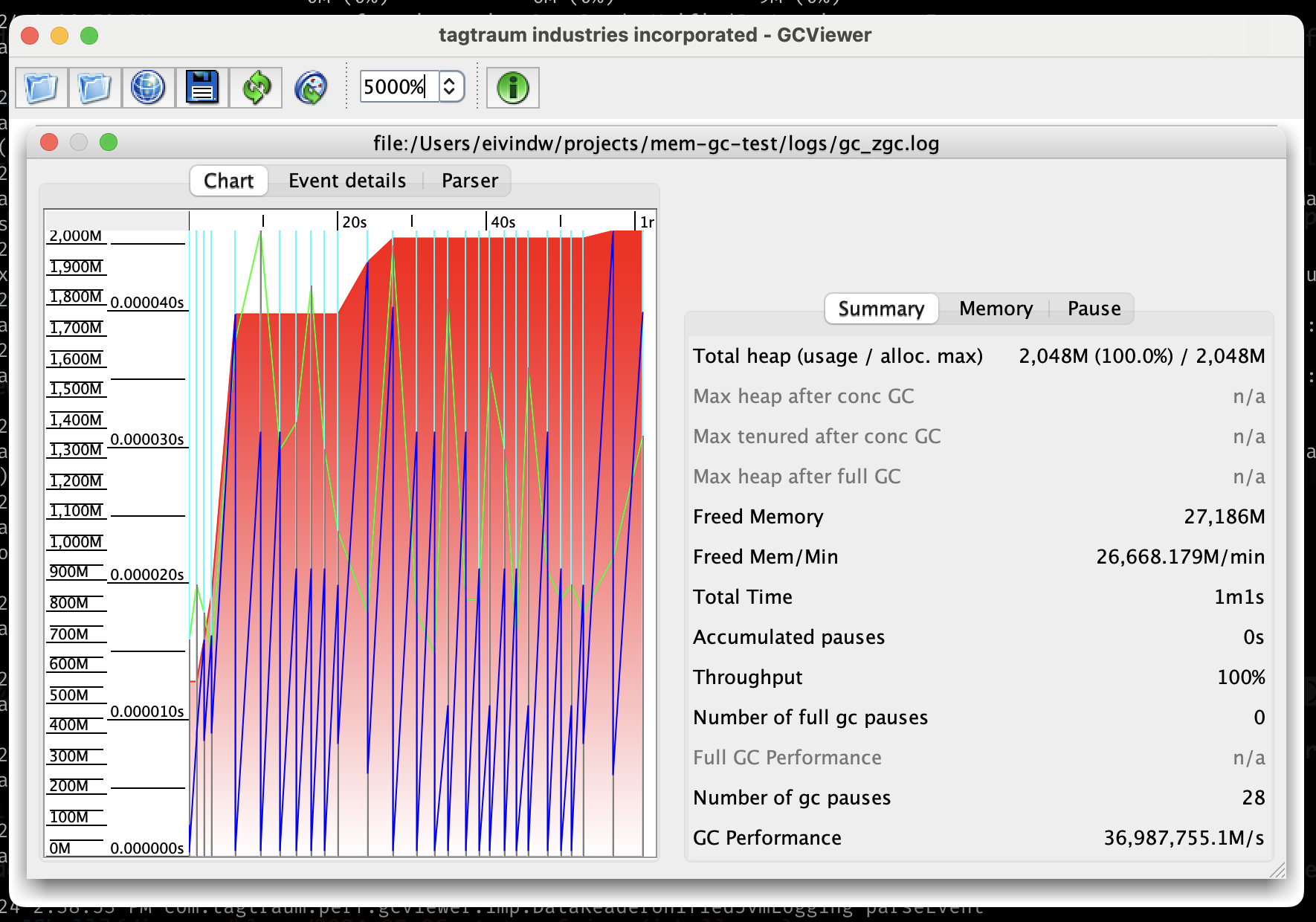
¶Sammenligning for test-applikasjon
Her viser jeg skjermbilde av graf for Serial, Parallel, G1 og ZGC (Shenandoah likte ikke GCViewer og Epsilon er meningsløs her). Dette er min lille test-applikasjon med maks heap satt til 2 GB. Den kjører i ett minutt og lager masse garbage. Noen kommentarer til grafene:
- Den røde linjen viser total heap allokert
- Den blå linjen viser heap som er i bruk
- Svart linje betyr Full GC (pause)
- Cyan linje betyr inkrementell GC
- Grønne linjer viser lengden på all GC aktivitet
Dette sier egentlig ingenting om hva som fungerer i den virkelige verden siden det er en liten tulle-test-applikasjon, men viser litt av forskjellen på GC-implementasjonene på en visuell måte.
Serial GC
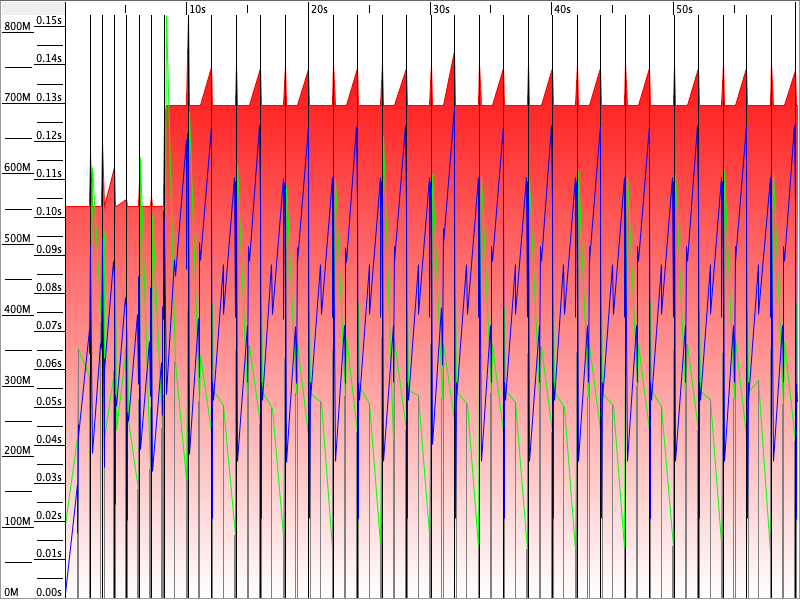
Med Serial GC er allokert heap på rundt 750 MB - kun ca. 200 MB opp fra utgangspunktet. Brukt heap svinger veldig jevnt mellom 150 og 700 MB. Som lovet i bruksanvisningen er dette det laveste minneforbruket av alle kjøringene. GC aktiviteten er veldig jevn, og den tar regelmessige pauser gjennom hele kjøringen.
Parallel GC
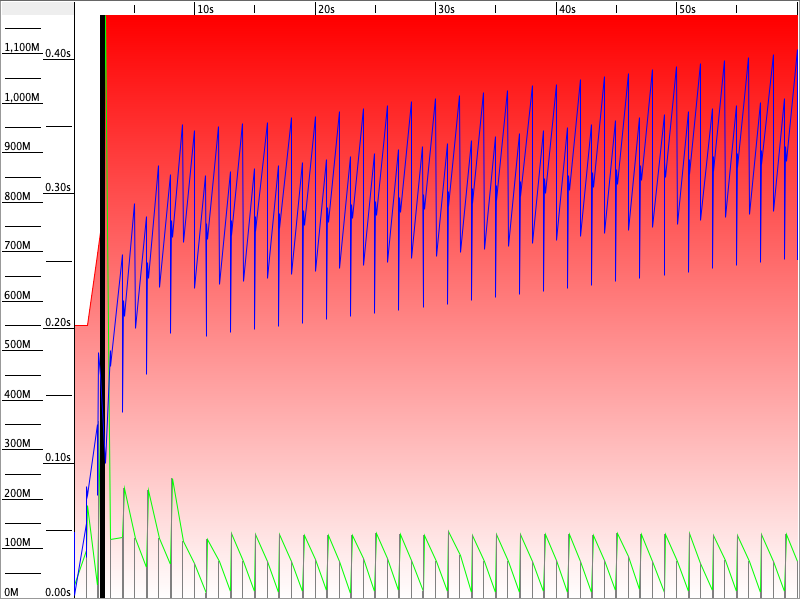
Med Parallel GC smeller den til med en dobling av allokert heap rett i starten - noe som koster en del pause (eller kanskje det er all pausen som fører til mer allokering?). Deretter kjører den jevnt og trutt med små kjappe pauser. Det som er interessant her er måten brukt heap øker gjennom hele kjøringen. Jeg tipper om vi hadde latt den gå noen minutter til så ville den doblet allokert heap igjen til den når maks på 2 GB og deretter måtte den tatt lengre pauser for å klare å frigjøre nok. Jeg ble så nysgjerrig at jeg testet 3 minutter:
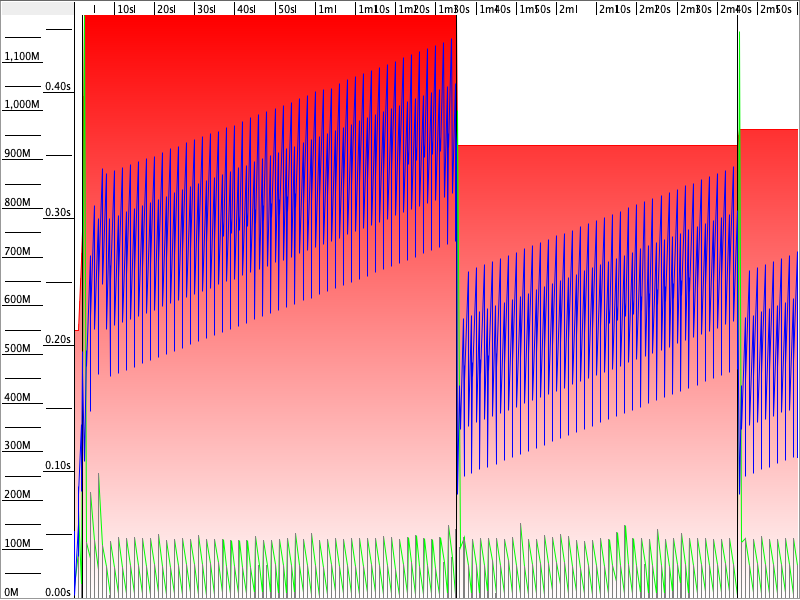
Ikke helt som jeg forutså, men den liker tydeligvis å ta litt større pauser innimellom for å reallokere heap og frigjøre alt - også stiger brukt heap jevnt og trutt igjen med små GC pauser igjen.
G1
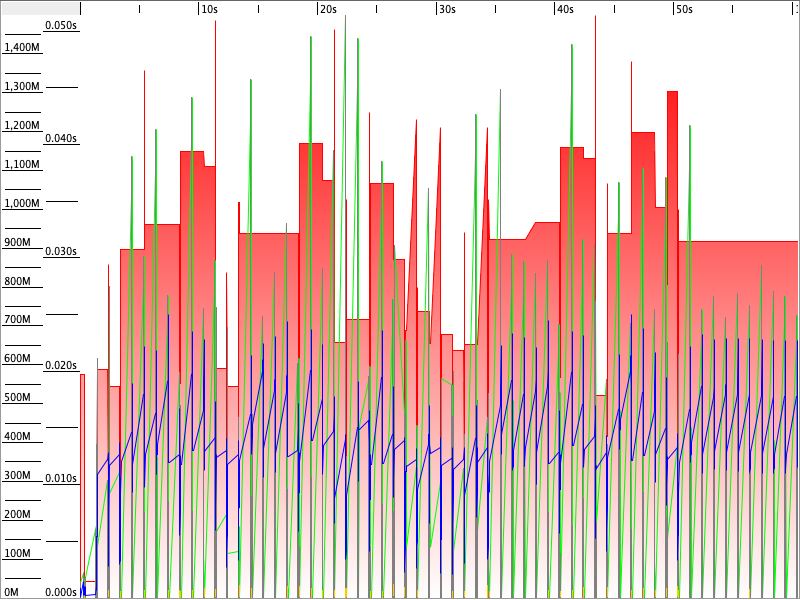
Man ser kjapt at G1 er den mest avanserte implementasjonen. Den reallokerer hyppig og raskt, mens brukt heap aldri egentlig går over 700 MB. Den tar nesten ikke pauser, men har hyppig og konstant aktivitet på GC.
ZGC
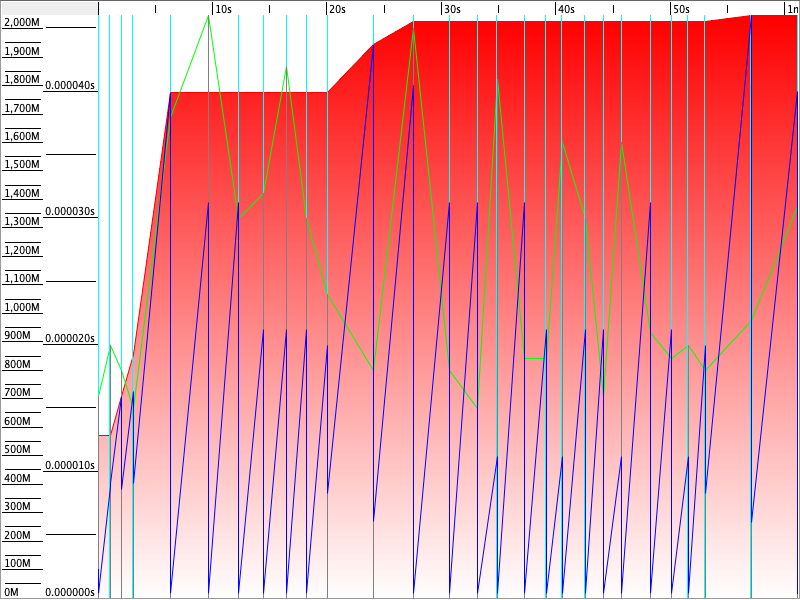
ZGC har veldig forskjellig mønster fra de andre. Den allokerer maks heap i løpet av kjøringen, og lar brukt heap også komme helt opp i maks før den frigjør plass. GC aktiviteten er ekstremt høy - så det stemmer nok at den bruker mye CPU på å få til dette her omtrent uten å ta pauser. Og de pausene den tar er ekstremt korte.
Oppsummerte tall
Fra oppsummeringene har jeg forsøkt å trekke ut en del tall for hver kjøring. Vi ser egentlig bare mye av det samme som beskrevet i grafene:
| Serial | Parallel | G1 | ZGC | |
|---|---|---|---|---|
| footprint | 825 M | 1 178 M | 1 500 M | 2 048 M |
| avgPause | 0.06122 s | 0.03492 s | 0.00801 s | 0.00003 s |
| minPause | 0.01233 s | 0.00061 s | 0.00003 s | 0.00001 s |
| maxPause | 0.15313 s | 0.43273 s | 0.05142 s | 0.00005 s |
| accPause | 8.75 s | 3.28 s | 3.49 s | 0 s |
| throughput | 85.47 % | 94.54 % | 94.23 % | 100 % |
Her er tilsvarende tall for omtrent samme kjøring i Java 8 på min gamle MacBook Pro med Intel Core i7 2.8Ghz CPU. Ser ut som M3 Pro som jeg kjører med nå er noen størrelsesordener raskere:
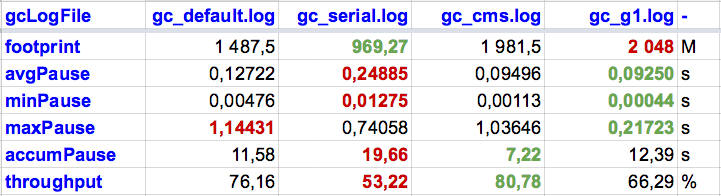
Artig å se at Serial og Parallel (default i gammel) er gode og dårlige på nøyaktig det samme. G1 har nok endret seg mye - og viser ganske mye bedre tall nå. I tillegg er CMS ut og ZGC kommet inn som et fint alternativ om man trenger super-lav responstid fra applikasjonen.
¶Oppsummert
Det har skjedd mye på GC-fronten i JVM de siste årene. Det kan være verdt å ta en titt på hvordan GC yter på ditt system - veldig mye man kan skru på her. Det finnes masse JVM argumenter for å finjustere hvordan for eksempel G1 (eller andre GC-implementasjoner) oppfører seg - så man kan prøve forskjellige innstillinger og måle forskjellen.
For de fleste applikasjoner er nok standard G1 et godt og trygt valg, men det finnes altså en del alternativer for spesifikke behov.
